Master Version Control in Data Science with our comprehensive guide. Elevate your project's accuracy,...
data science
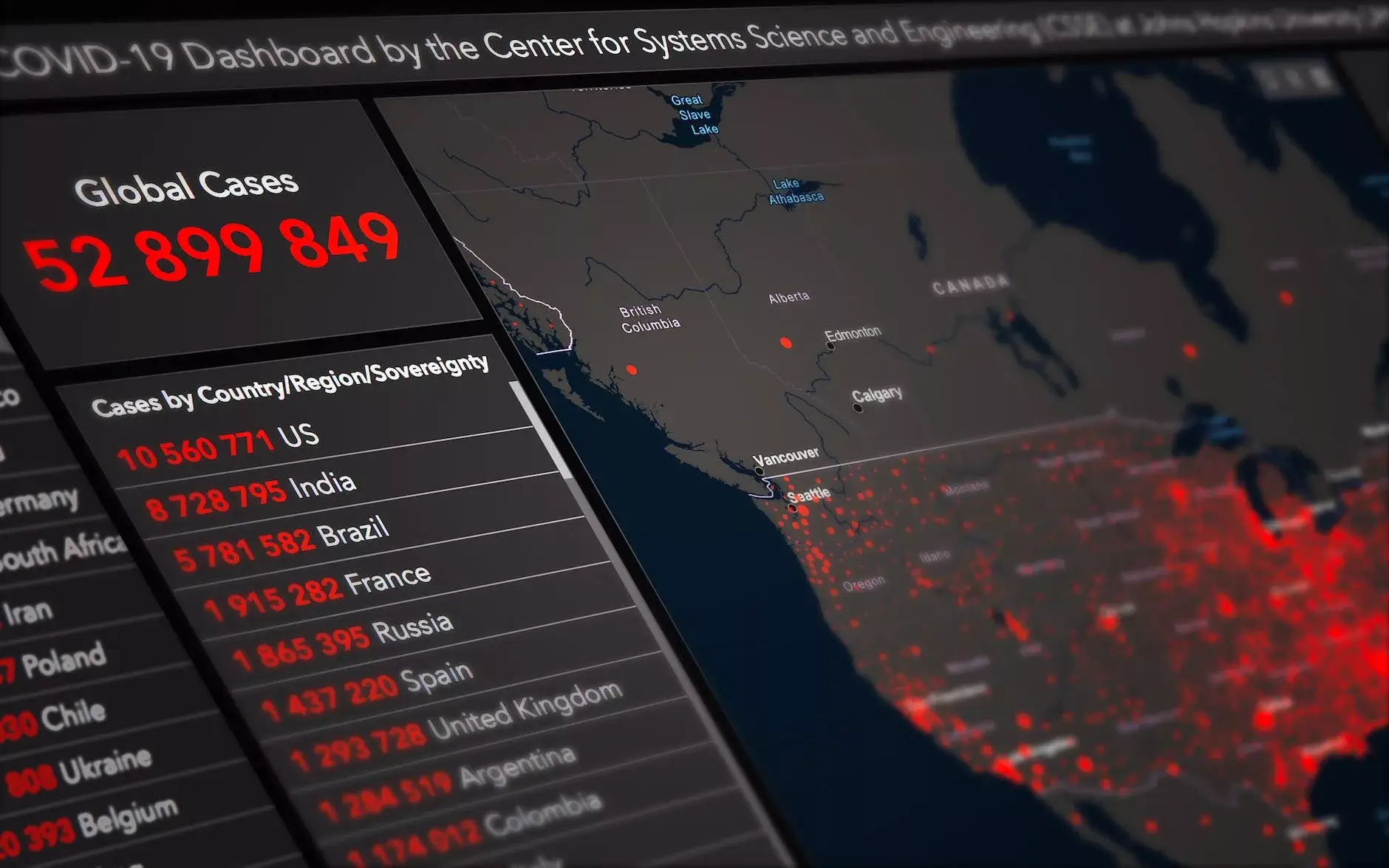
Discover how data science helps businesses to gain a competitive edge.

Discover effective strategies and resources to learn data science in 2023 from scratch. Get...

Unlock the potential of your organization's data with a comprehensive data strategy that drives...

This article presents a comprehensive data science roadmap for 2023, outlining the key...

Learn where to get Data Science Explained Simply and unlock the potential of this...